








app.build is evolving into something new
Since publishing this post, we’ve shifted focus. The managed version of app.build has been discontinued, but the source code is available - if you’re also building an agent, you can still explore the app.build agent and platform code for reference and implementation examples. We’re also applying this learnings and code to our next project.
TL;DR: We built app.build, a reliable open-source AI code generator by: limiting initial scope to CRUD web apps, using FSM-guided tree-search actors, implementing extensive validation, and encapsulating context management using an error analysis feedback loop.
These architectural choices weren’t arbitrary—they emerged from a fundamental decision about what kind of system we wanted to build. Let’s start with the core philosophy that shaped everything else.
Philosophy: Reliability vs Capabilities
One of the core principles in system design is identifying key tradeoffs. In the code generation context, the most important one is capabilities (how advanced the generated features can be) versus reliability (how likely they are to work).
Consider these two extremes:
- High reliability, limited capabilities: When you define types in an ORM and those automatically appear in the database through generated migrations, reliability approaches 100%, but the feature set is very limited.
- High capabilities, low reliability: A tech-savvy user prompting an LLM-based assistant can request any advanced feature, but it may fail in obvious ways—or worse, in implicit ways.
Many AI app builders have emerged recently, supporting a wide range of applications (partially limited by tech stack). Coding assistants and AI-powered IDEs like Claude Code and Cursor don’t even limit your choice of programming languages, despite performing better with popular ones. Unfortunately, neither approach guarantees a final working result (especially in the single shot mode), though they do empower users in the process.
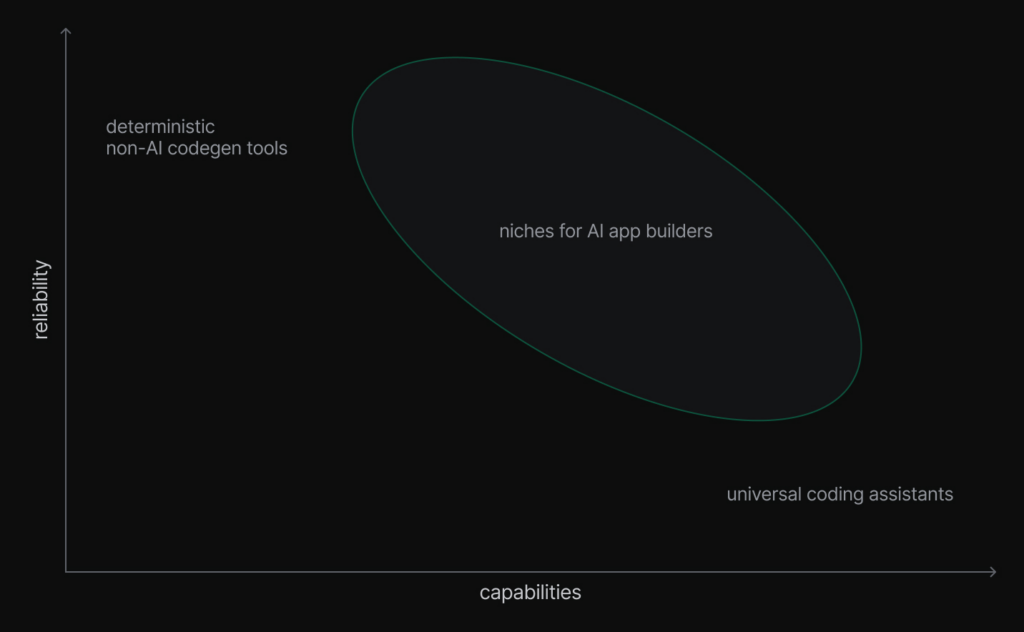
When working on app.build, we set reliability as our core value, even if it meant sacrificing advanced features for the initial release. We wanted to echo the principle popular in some tech communities: “if it compiles, it works.”
Generalization through Specialization
Since app.build was kicked off at Neon (a database company), we started by focusing on the typical OLTP use case—CRUD web apps. Yes, we wouldn’t support building anything user may want, but the final artifacts should be well-functioning—ideally without human intervention, or at worst, requiring only a gentle touch from the user.
By fixing both the stack and the niche, we could restrict AI generation and introduce a reliable validation pipeline. Our core proposition is the following:
- We keep the agent narrow, very opinionated and thus reliable.
- With reliable agents available, we will widen the scope via horizontal scaling – supporting new stacks and application types
Support for new tech stacks is already work in progress. For every new vertical, we’re going to stick to our core value: the resulting apps should be usable and pass smoke tests (e.g., end-to-end tests with tools like Playwright).
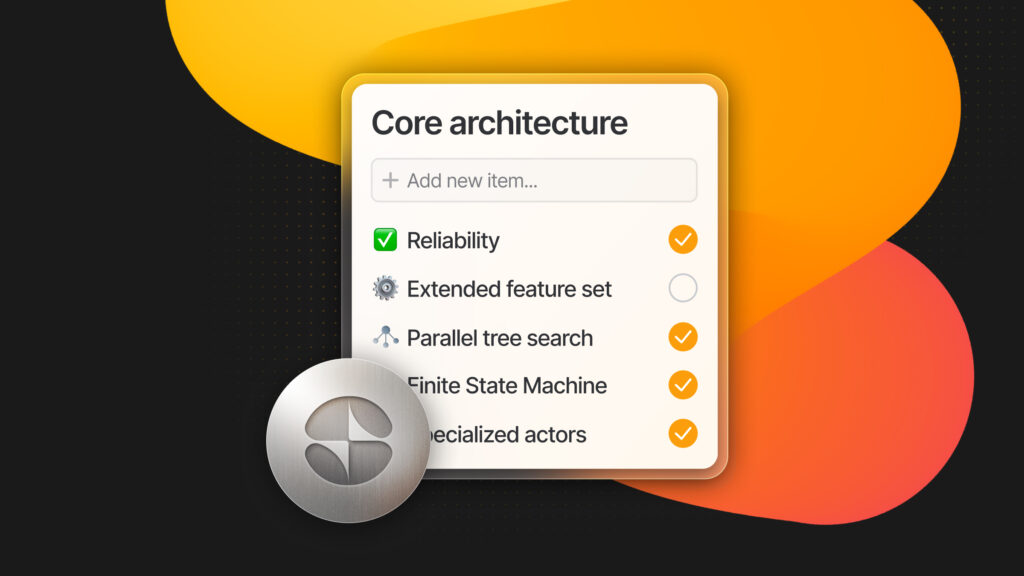
Core Architecture
With this reliability-first philosophy established, let’s examine how we translated these principles into our core architecture.
Under the hood, app.build uses three key components
- a Finite State Machine (FSM) for flow control
- parallel tree search for finding solutions
- specialized actors for different tasks
While this sounds complex, each piece serves a simple purpose.
Evolution from Linear to Graph-Based
Our very first version was a linear workflow with one step following another. We realized decomposition was key, so we started with sequential generation and gradual context enrichment: data model first, ORM code later, followed by tests and handlers. This worked fine for initial demo apps but quickly became too restrictive.
The main limitation? No intervention was possible. If an intermediate result didn’t match expectations, users could only start from scratch—not the ergonomics nor the velocity we were aiming for!
This prompted the next idea: transform the linear pipeline into a graph, granting the required flexibility. Since we needed to combine flow control with guardrails, we introduced a Finite State Machine (FSM). With FSM, we could restrict the level of feedback—the FSM driver (a top-level agent) could only send guiding events instead of imperative-style control. Using FSM for agentic tasks becomes a popular topic these days, as StateFlow and MAPLE suggest.
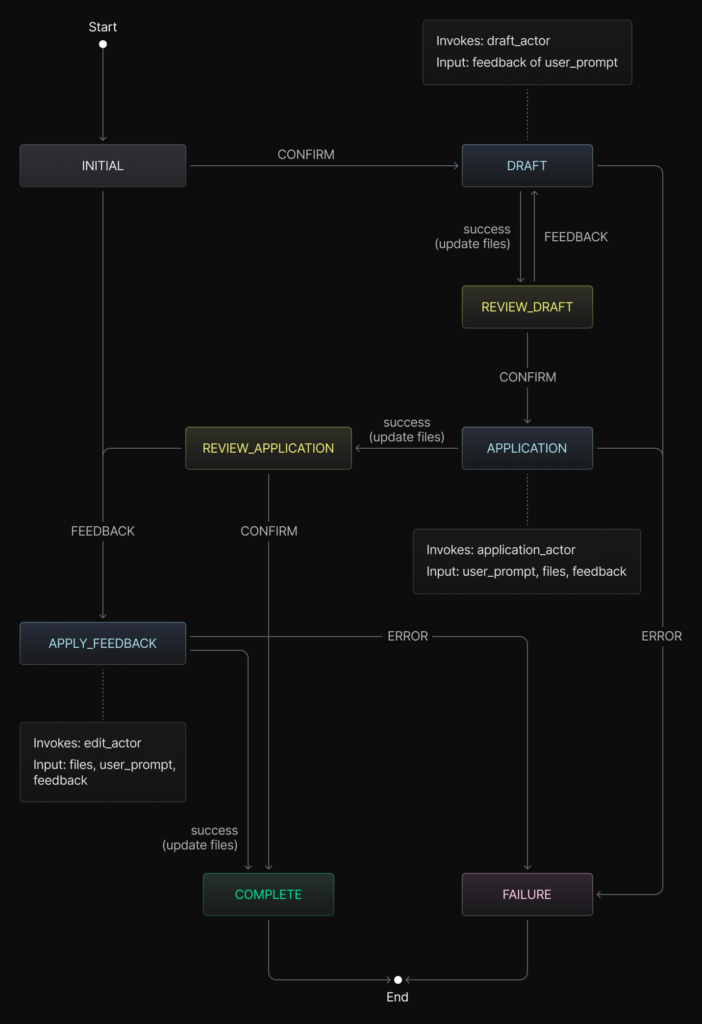
Actors and Concurrent Execution
The FSM itself doesn’t generate anything; it delegates work to actors—subagents focused on solving particular problems. Our initial release includes four actor types:
- DraftActor – for initial data model generation
- HandlerActor – for backend logic
- FrontendActor – for UI code generation
- EditActor – for subsequent changes
Some actors can run concurrently. For example, we can spawn 20+ actors working on various handlers while one builds the frontend for a single app. Ideally, we’d like to decompose the FrontendActor further so multiple instances could work on specific components—currently, frontend generation often dominates the total app generation latency (because we do it all at once).
Concurrency execution is instrumental in this design. Universal tools improving the quality of modern LLM apps are typically associated with larger context or more computational budget (either with reasoning or parallel searches, both are compute-heavy). Our design allows us to tune this knob and get reliable results without wasting hundreds of millions of tokens. Additionally, the validations pipeline described below tends to affect the final latency too, so the agent would never be usable without concurrency support.
The Search Process
Each actor’s main job is to search for the solution, and modern research suggests that tree-based search can improve final quality by a large margin. The search process maintains a tree of generation attempts, where each node represents a potential solution state. Key features include:
- Early termination when any candidate passes all validation stages
- Dramatically reduced generation time for successful paths
- Tailored search parameters (depth vs breadth preference, beam width)
- Task-specific validation checks
Each actor works in an isolated environment, following the encapsulation principle. Each actor owns its own LLM message chains with required context. Reliability is achieved through the validation pipeline—no actor can return a solution unless it passes all checks.
The Special Case: EditActor
EditActor deserves special mention. It appeared later than others because our first versions (with the aforementioned linear workflow) could only perform a single shot of an app generation.
Our evolution:
- First hacky workaround: refine the data model first, then rerun generation
- Experimented with advanced FSM transitions
- Final realization: straightforward file editing works fine if the project structure is properly set during initial generation
Unlike most actors, EditActor has more flexibility, because its scope can be really huge for some changes (e.g., when the initial model needs changes that are later propagated across components) and minor for others (e.g., “change the header color” translates to a single line change). Similarly to the FrontendActor, it uses tools for more agentic behavior to rely on existing files. Those properties affect the actor’s convergence negatively, but given it starts the work with established project structure and validation pipeline, it is not a blocking problem.
Stateless Nature of the Agent

Designing the agent service in a scalable manner was one of the software engineering challenges that resulted in our decision to go stateless. We achieved that by supporting only in-memory transient sessions while serializing / deserializing state from the payload. All the parts mentioned above are very inline with such an approach: an FSM state changes are atomic transactions, and the actors’ inner state is serializable. Stateless apps are very easy to scale, so our production infrastructure was straightforward: a single Docker image deployed to AWS ECS with autoscaling support. The only non-trivial aspect of it was the need to provide a Docker socket inside the application, so our isolated sandboxes could be spawned outside of the main app container.
Top-Level Agent
Even when the FSM could produce viable apps, we weren’t sure about the user interface. It worked fine with an initial prompt, but writing great initial prompts is a rare skill (we fail at it too often!).
Our journey to the current solution:
- First attempt: Separate prompt refinement step at the beginning (limited value)
- MCP experiment: Wrapped FSM in an MCP server, controlled via MCP clients like Cursor or Claude Desktop (didn’t feel right)
- Final solution: Separate top-level agent that gathers details from users and passes them to the core generation machine
This approach aligned with other agents in the market (familiar UX for users), and matches our context encapsulation design. The top-level agent focuses on user needs and communication without handling technical details. It has limited tools to propagate these needs, creating a combination of:
- Controllable, restricted API
- Flexible communication allowing users to refine requirements as needed

Interesting fact: a top-level agent does not need to be too advanced. We currently use gemini-flash in our managed service for its balanced AI capabilities and latency; with more advanced models, we even observed behavior that is “too picky” behavior – better instruction following made them act as truly harsh critics significantly affecting overall latency.
The top-level agent works fine as a base defense line keeping us from unwanted usage. We did not have a dedicated red teaming process dedicated to prompt hacking, but overall naive approaches to misguide the agent and generate apps for illegal or unethical needs were not successful; the same applied for attempts to use an agent for irrelevant tasks (“hey, how to boil eggs?”).
Checks and Validations
Since we fixed the initial tech stack, we could implement solid checks to enforce app quality. TypeScript was our solid baseline—the language is well-known to all LLMs and provides an advanced type system and toolset to rely on.
Validation Evolution
Our validation pipeline evolved gradually, with each check addressing specific failure modes:
- TypeScript compilation – The obvious starting point
- Unit tests – Ensured backend API handlers do what they’re supposed to do; enforced separation of concerns. LLMs are widely used in the industry to improve test coverage, and adding this step was crucial for app.build as well.
- Linters with custom rules – Addressed LLM-specific failure modes (especially in the Sonnet 3.x era), such as:
- Using mocks to bypass tests
- Tricks with renamed imports
Some of those errors evaporated after the base models were updated. However, some are still valuable – e.g., a rule checking for empty values on the frontend fixed many UI issues.
- Playwright end-to-end smoke tests – Enforced consistency between user prompts and generated apps; caught client-side errors that passed previous checks
We kept Playwright as the last check for performance reasons—while linters run in under 100ms, Playwright tests typically require seconds.
The current validation pipeline is solid, but should not be considered as a final revision – additional types of checks (e.g. property testing) can be introduced later to reduce the long tail of runtime errors happening to exotic generated apps.
Context Engineering
Validation catches errors after generation, but prevention is better than cure. The key to reducing failures lies in what information we provide to our actors—and how we structure it.
AI engineers these days avoid the term “prompt engineering” because it doesn’t really reflect the whole stack. For any modern LLM app, writing a good prompt isn’t enough—prompts aren’t magic spells, and AI engineering isn’t the Harry Potter universe.
Early prompt engineers searched for the most effective phrases to express their needs in ways understandable by LLMs. Context engineering, however, is broader in scope: it defines what information is needed for LLM operations and how to structure it. Today, the specific wording in a prompt barely matters, but writing detailed instructions and maintaining relevant context is crucial.
At the same time, overloading the context is a mistake—longer contexts mean less attention to important details and higher latency. Despite modern LLMs being able to handle large contexts in theory, empirical tests like “needle in a haystack” demonstrate potential drawbacks.
Our Context Preparation Principles
- Encapsulation is key – Each step should only be familiar with the parts of the project relevant to that step. Unreasonably long context has three ways to make things worse: higher latency, higher costs for the API, and – most importantly – attention layer dilution leading to degradation of the final result.
- Dynamic user prompts, cached system prompts – User prompts should be short and dynamic, while system prompts can be longer due to prompt caching. We use Jinja2 templates to fill user prompts with project-specific details.
- System prompts for common failures – System prompts can cover typical failures and provide guidance on tech stack nuances where LLMs struggle.
- Semi-automated prompt writing – Most examples and rules in our system prompts were LLM-generated based on logs from failed app generation sessions. This feedback loop helped us solve many common issues in a short period. (Eventually, we’d like to automate this in a continuous manner from production logs.)
Example: Type Matching Guidance
Postgres, Drizzle, and Zod have somewhat different default types for the same semantics. Popular failure modes include:
- Decimal values (often used for money-related data in business applications)
- Confusion between nullable and optional fields
Both issues were extracted from debug logs by the LLM (kudos to the Gemini team and their 1M context window!) and later added to the system prompt here.
Overall, the idea of feeding the context with a few high-quality examples of user prompt – code pairs proved to be very effective in increasing the success rate of the code generation. Those who want to reduce the amount of manual work like writing those high-quality examples could leverage Deep Research-like tools. A single prompt like “analyze the docs on TECH STACK OF YOUR CHOICE, its typical usage and problems; based on that generate a detailed prompt on how to use it for AI software agent” can provide you with a really solid baseline for system prompt.
In the future, we plan to advance the context management towards more automated ways, inspired by TextGrad and other text “differentiation” frameworks.
Tools We Rely on
While our architectural decisions were crucial, none of this would have been possible without choosing the right foundation. Several key tools enabled our approach and deserve recognition for making the entire system viable; others were important during the exploration:
- Modern TypeScript ecosystem – Made the whole solution possible. The combination of Drizzle, tRPC, and Zod was crucial for consistency.
- uv – We started with raw requirements.txt and switched to uv later. It’s blazing fast and totally worth it for any Python project. We rate it a 10/10, and fully recommend it. Astral is doing a great job building modern tooling for Python devs.
- Dagger – Our second sandboxing solution (started with classic Docker). Provides a modern, agent-native approach: chaining methods with effective caching instead of manual container maintenance. Special features:
- Restricted file paths prevent actors from hacking rewards by drifting from project structure
- Elegant DevEx despite being a risky bet for production – we had a kind of adventure fixing concurrency issues too close to the release date. However, currently we consider it stable enough.
- Langfuse – Used for LLM tracing (and cost analysis), generally happy with it. However, we have been changing our internal agent structure too often and didn’t always have time to attach proper tracing. Maybe we’ll give it a second chance now that our code structure is more stable, as the current tracing situation is very basic.
- TypeSpec – Early experiments with using TypeSpec to define and later generate APIs were indeed promising, especially for complex apps with non-trivial logic. Furthermore, TypeSpec is very extendable, so one can add custom code emitters on top of the base specification – for instance, we connected it with Cucumber to support BDD. While it was not part of the main release, we found this approach very viable for the future development.
Summary and Future Directions
During this project, we achieved our initial goal: creating reliable apps deployable to Neon’s infrastructure. The limited scope of full-stack CRUD web apps helped us ensure quality. At the same time, we fully understand this approach’s limitations, and are currently working on a more universal solution, enabling users to build more advanced apps using their favorite technologies.
Among the error logs, we’ve observed clear evidence of users’ needs for more flexibility. The lessons learned during this first version will help tremendously as we expand!
Give app.build a try on the managed service or hack around locally with our fully open-source code!


