









note
This is a cross-post of an engineering blog that was originally published on Databricks. Neon and Databricks Lakebase both run on the same technology, and this engineering optimization benefits customers of both platforms.
In Neon's lakebase architecture, compute and storage are separated by design. While this separation was originally built for operational flexibility, including scaling, branching, and instant recovery, it also unlocks a massive performance frontier.
By decoupling these layers, we can offload work from your Postgres compute to our distributed storage in ways that are structurally impossible in traditional, monolithic Postgres deployments. In this post, we will explore how we exploited this architectural advantage to eliminate a decade-old Postgres bottleneck to improve Postgres write throughput by 5x, while reducing read tail latencies by 2x and WAL traffic by 94%.
The hidden cost of traditional Postgres durability
To understand how we achieved a 5x improvement in managed Postgres performance, we have to look at how traditional Postgres handles durability.
In Postgres, every database change is first saved to a sequential log (the Write-Ahead Log, or WAL) to ensure data isn't lost in a crash. To keep crash recovery times fast, Postgres periodically performs a background cleanup event called a "checkpoint." Unlike a snapshot, a checkpoint is simply a milestone marker in the log. During a checkpoint, Postgres takes all the modified data currently in memory (managed in 8KB chunks called "pages") and flushes it to the main disk, up to a specific point in the log. If a crash happens, Postgres restores your data by starting at that checkpoint milestone and replaying the recent WAL logs over the disk.
However, there's a risk: if the server crashes exactly while saving an 8KB page to disk, the page might only get partially written, resulting in a corrupted "torn page." If Postgres tries to replay a tiny log update over a torn page, the data is permanently ruined. To fix this, Postgres has to ensure it never relies on a corrupted disk for recovery.
It does this using a "Full Page Write" (FPW). The very first time a page is modified after a checkpoint milestone, Postgres doesn't just log the tiny change; it copies the entire 8KB page into the WAL. If a crash happens and the disk page is torn, Postgres ignores the ruined disk, grabs the pristine 8KB backup from the WAL, and uses that as the perfect starting point to replay the rest of the logs. While this guarantees absolute safety, it is expensive: on write-heavy applications, logging entire 8KB pages can inflate log volume by up to 15x, often becoming the system's biggest performance bottleneck.
Neon storage eliminates the risk of torn pages
In Neon your compute is stateless. It does not rely on a local data directory. Instead, it streams WAL to a Paxos-based quorum of safekeepers.
Because there is no local-disk page to tear, the failure mode FPW was designed to prevent simply does not exist. However, naively turning off FPW creates a secondary problem: read performance. Without those periodic full page images in the log, the storage layer would have to replay an infinitely long chain of small deltas to reconstruct a page for a read request. What was once a bounded O(checkpoint frequency) replay becomes an unbounded chain, leading to a spike in read latency and resource consumption.
Image generation pushdown to distributed storage
We solved this by moving the intelligence from the compute node to the storage layer. We call this image generation pushdown.
When Postgres compute requests a page from storage, the pageserver (a component of Neon's distributed storage system) reconstructs it by finding the most recent materialized image of that page and replaying any WAL deltas on top. The full page images that the compute used to embed in WAL doubled as periodic reset points in that delta chain, naturally keeping the chain reasonably bounded and reads fast. For a deeper treatment of this mechanism, see Deep dive into Neon storage engine.
With full page writes disabled, those reset points disappear. Without additional intelligence in the distributed storage system a frequently-updated page could accumulate a long chain of small deltas with no intervening image. The result would be an undesirable increase in read latency and resource consumption as the pageserver replayed the entire chain to serve a read, increasing latency and resource consumption.
To avoid this problem we pushed down the image-generation responsibility from the compute's WAL stream into the storage layer, preserving the bounded read behavior of storage while still eliminating the WAL overhead on the compute. The pageserver now generates full page images when a page has accumulated more delta records than a configured threshold without an intervening image. This is a naturally better approach because the decision to generate a new image is based on the actual number of changes to a page rather than the unrelated Postgres checkpoint process.
Here's why this is significantly better for performance:
- Network efficiency: The compute sends only the compact deltas, which are the actual changes, leading to a 94% reduction in traffic in our benchmarks.
- Scalability: Work is moved from the single Postgres writer to the distributed, independently scalable storage layer. Image generation for a project branch is now shared across multiple pageservers in the background.
- Optimal reads: When images are generated is now based on actual changes to a page rather than the unrelated Postgres checkpoint process.
Quantifying the impact: from lab to production
We benchmarked this optimization using HammerDB TPROC-C (a TPC-C derived OLTP benchmark) and validated the results across real-world production workloads.
1. Serverless compute scaling
Throughput is measured in new orders per minute (NOPM). The gains scale dramatically with the size of the compute instance:
| Compute size | Before (NOPM) | After (NOPM) | Throughput gain |
|---|---|---|---|
| 4-vCPU | 78,876 | 94,891 | 20% |
| 16-vCPU | 95,832 | 269,189 | 2.8x |
| 32-vCPU | 95,686 | 439,300 | 4.5x+ |
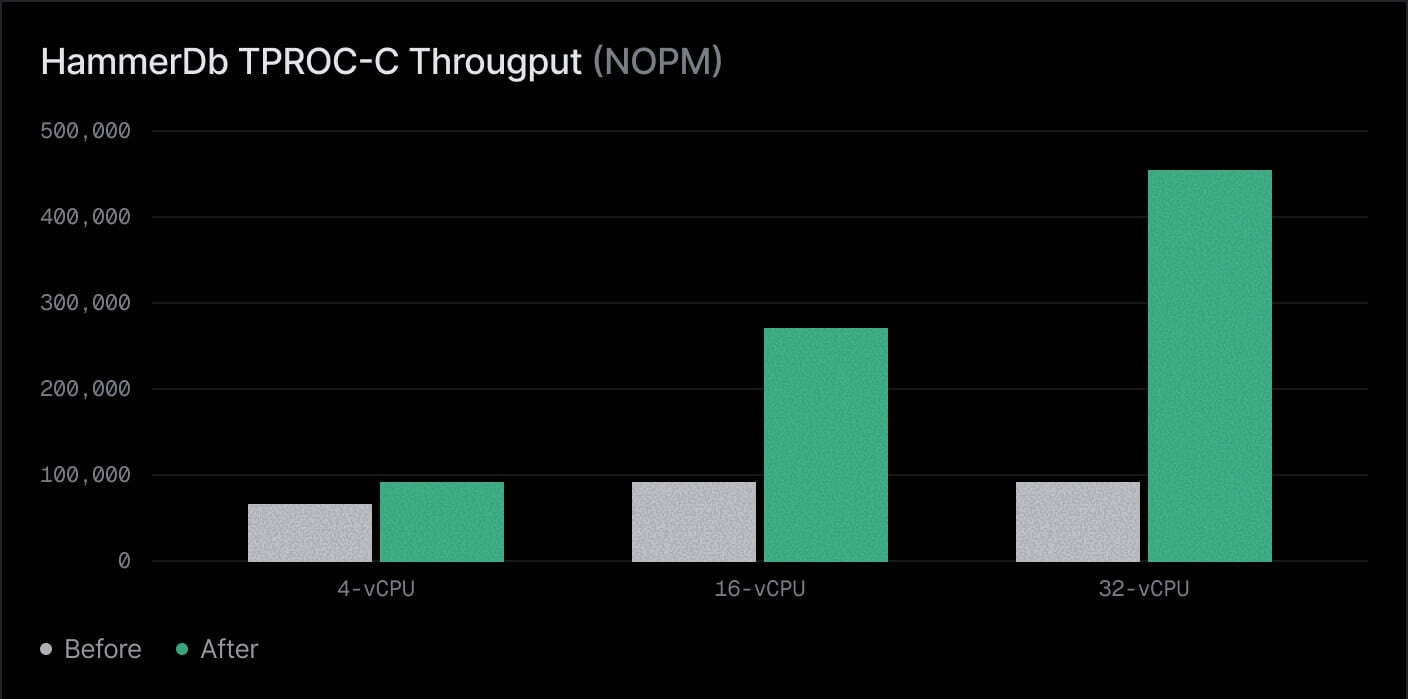
On a 32 vCPU compute, the improvement exceeded 450%.
With full page images generated on compute, each transaction generates 58Kb of WAL on average. With image generation pushed down, that drops to under 4Kb — a 94% reduction. The throughput improvement follows directly: less WAL means less contention on the write path, less network bandwidth consumed, and less work for the storage layer to ingest.
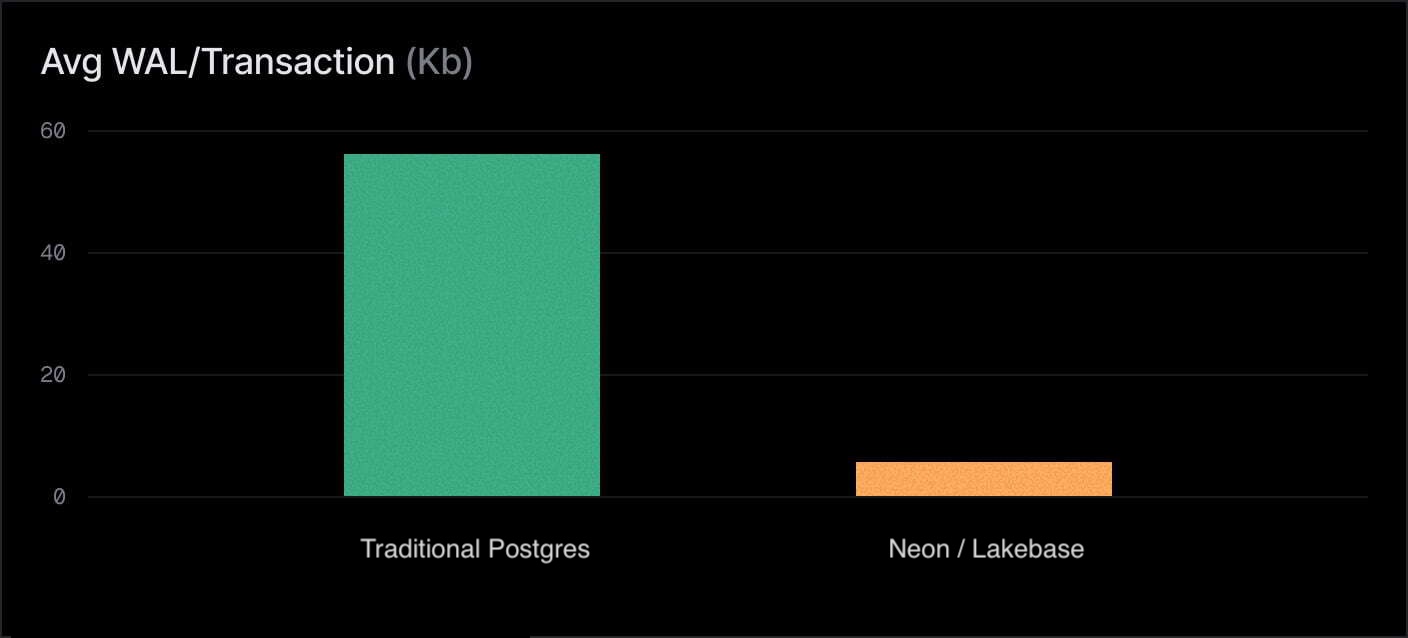
By removing Postgres's FPW bottleneck, we allowed throughput to scale linearly with compute resources. This is something monolithic Postgres struggles to do under heavy write load.
2. Real-world production validation
In a production environment for a high-profile 56 vCPU project, enabling image pushdown reduced steady-state WAL generation from 30 MB/s to just 1 MB/s.
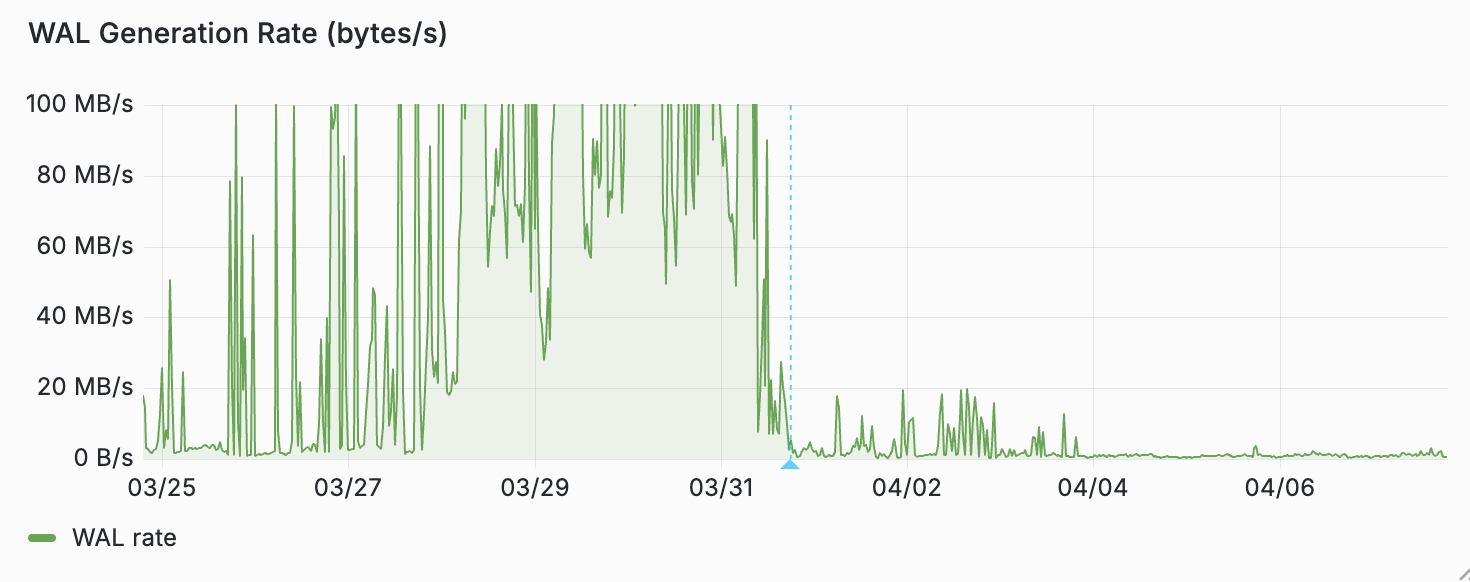 Prod customer WAL rate (lower is better)
Prod customer WAL rate (lower is better)
This decrease in volume correlated directly to increased transaction throughput during daily peaks.
This did not just help writes. By optimizing the delta chains, the number of WAL records that must be applied per read dropped significantly. We saw p99 read latencies drop by 30% to 50% and p50 latencies drop by approximately 30%.
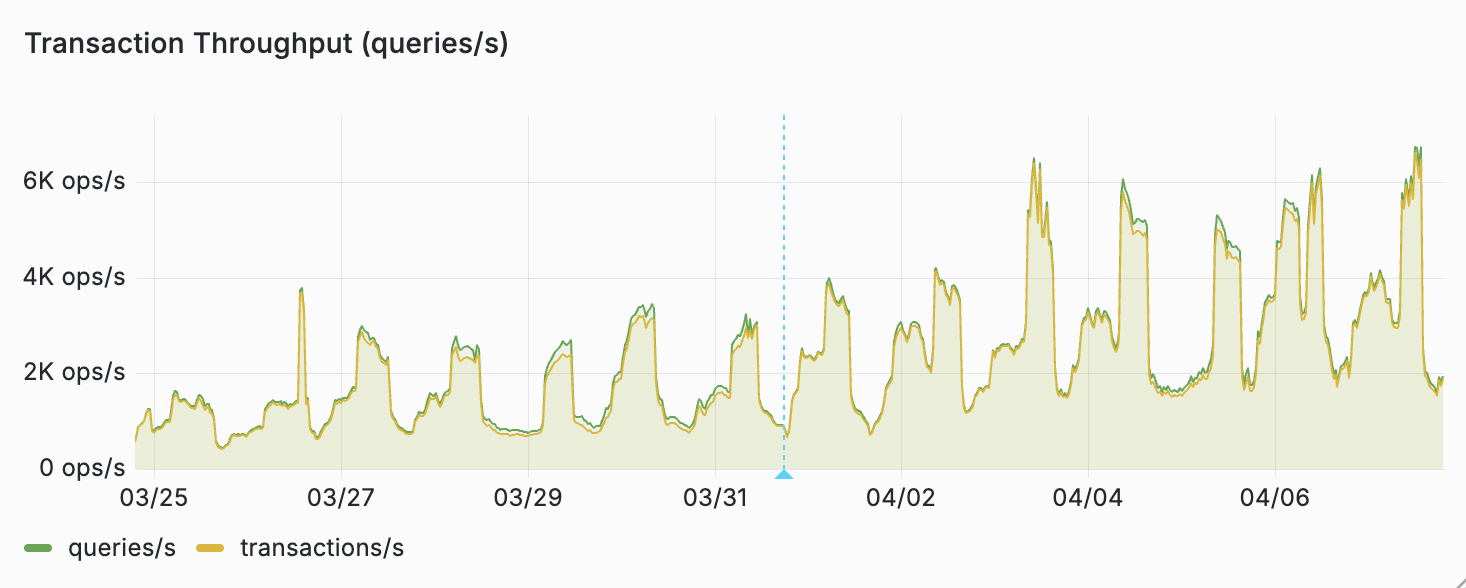
Prod customer throughput (higher is better)
Zooming out, at the regional level, post enablement we saw the total amount of WAL generated by computes drop by up to 4x. P99 latency of reads from the storage engine improved by up to 3x and became much more stable.
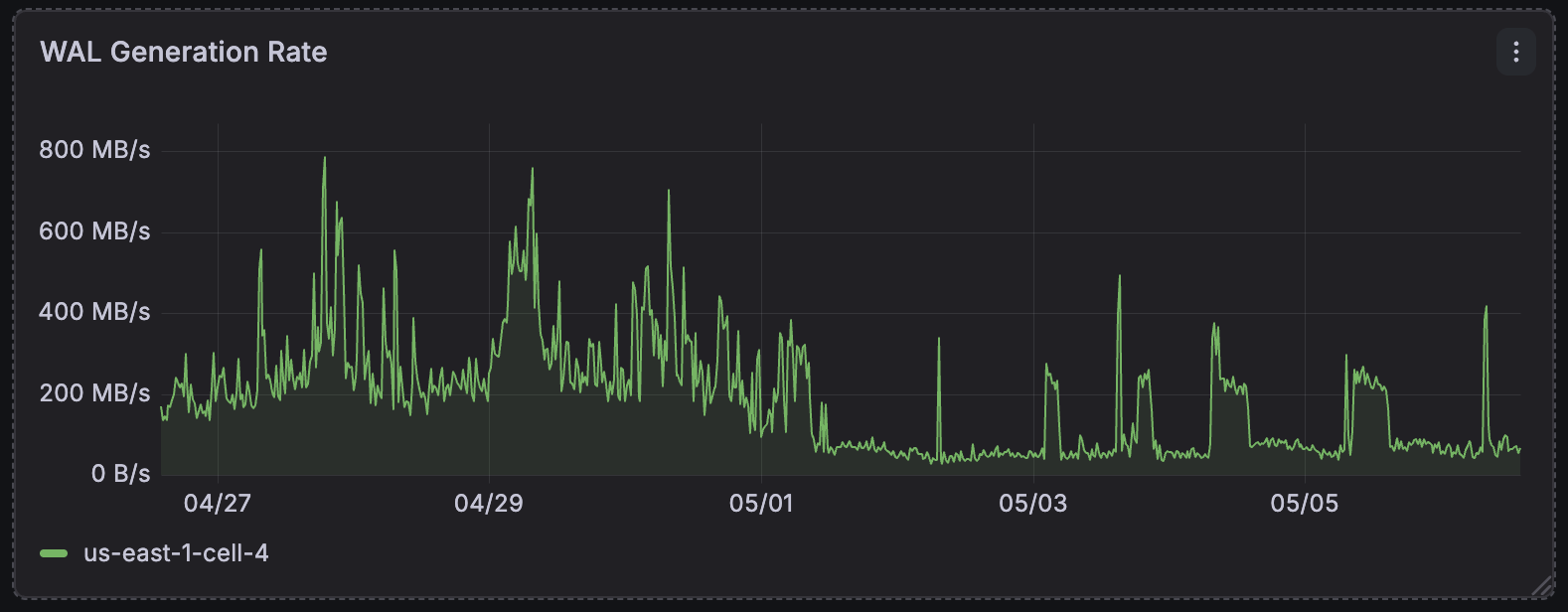 Regional WAL ingest rate (lower is better)
Regional WAL ingest rate (lower is better)
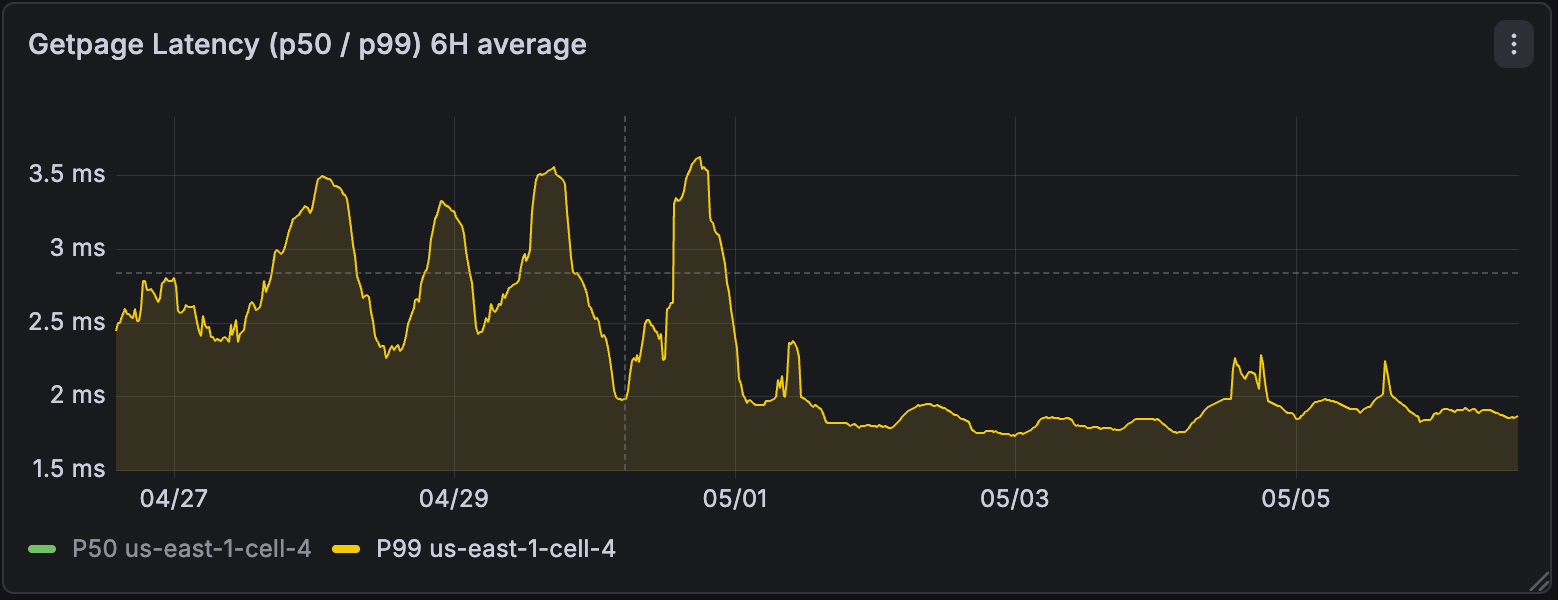 Regional storage p99 page retrieval latency (lower is better)
Regional storage p99 page retrieval latency (lower is better)
3. Synced tables
For data-intensive Synced Tables (A special feature of Databricks where analytics tables are automatically synced to Postgres), the impact was immediate. One customer saw ingestion throughput jump from 17k rows per second to 62k rows per second, which is a 3x increase, simply by enabling image pushdown.
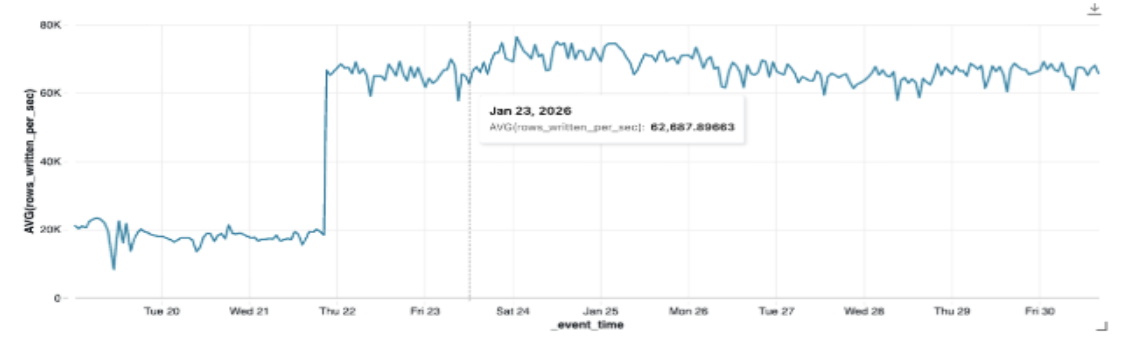 Prod customer sync table (higher is better)
Prod customer sync table (higher is better)
FPW's seamlessly turned off for all databases
Since late March, we have rolled this out across our entire fleet. It is now active for all Neon databases globally.
The change was applied to running computes via our control plane and storage system, which coordinated the transition automatically. This was achieved using the existing Postgres XLOG_FPW_CHANGE WAL record mechanism, meaning no restarts or interruptions were required for our customers.
What's Next
Neon's lakebase architecture was built for flexibility, but it was designed for performance. Pushing down full page writes is part of a systematic effort to harvest the benefits of storage and compute separation.
Just as we introduced cache prewarming for zero-downtime patching, we are continuing to move heavy-lifting tasks away from your transactions and into our scalable background storage stack. The Postgres write tax is officially a thing of the past.


