








Starting in May, we had a series of feature launches with agentic AI partners that gained far more momentum than we predicted. In two short timespans, the rate of new database creation increased more than 5x, and the rate of branch creation increased more than 50x. While we were humbled by the uptick, the significant burst in operational load caused a lot of strain in the Neon platform, manifesting as more incidents over the course of the two months than the entire year before.
We understand that databases are some of the most critical operational infrastructure for our customers, and stability is paramount. The problem should have never happened and I am embarrassed for this incident and sorry to cause pain to our customers and our team. In this blog post, we explain the underlying causes for these incidents and what we are doing to avoid these categories of incidents in the future.
May: Capacity Handling and “Cells”
May incidents were caused by us hitting a scaling limit around the number of active databases in US regions before our solution (Cells) was ready. Every active database on Neon is a running pod in a Kubernetes cluster. Our testing of Kubernetes showed service degradation beyond 10,000 concurrent databases. Among multiple issues discovered in testing, we approached the EKS etcd memory limit of 8GB and pod start time fell below our targets. In addition, in our us-east-1 cluster, our network configuration limited us to ~12,000 concurrently active databases.
In January 2025, we forecasted that we would hit these limits by the end of the year. While we believe that we can iterate on our Kubernetes configuration to vertically scale higher, there are many reliability and resiliency advantages to a horizontally-scaled architecture.
As a result, we started working on a horizontally-scalable architecture called “Cells” where each region can have multiple Neon deployments.
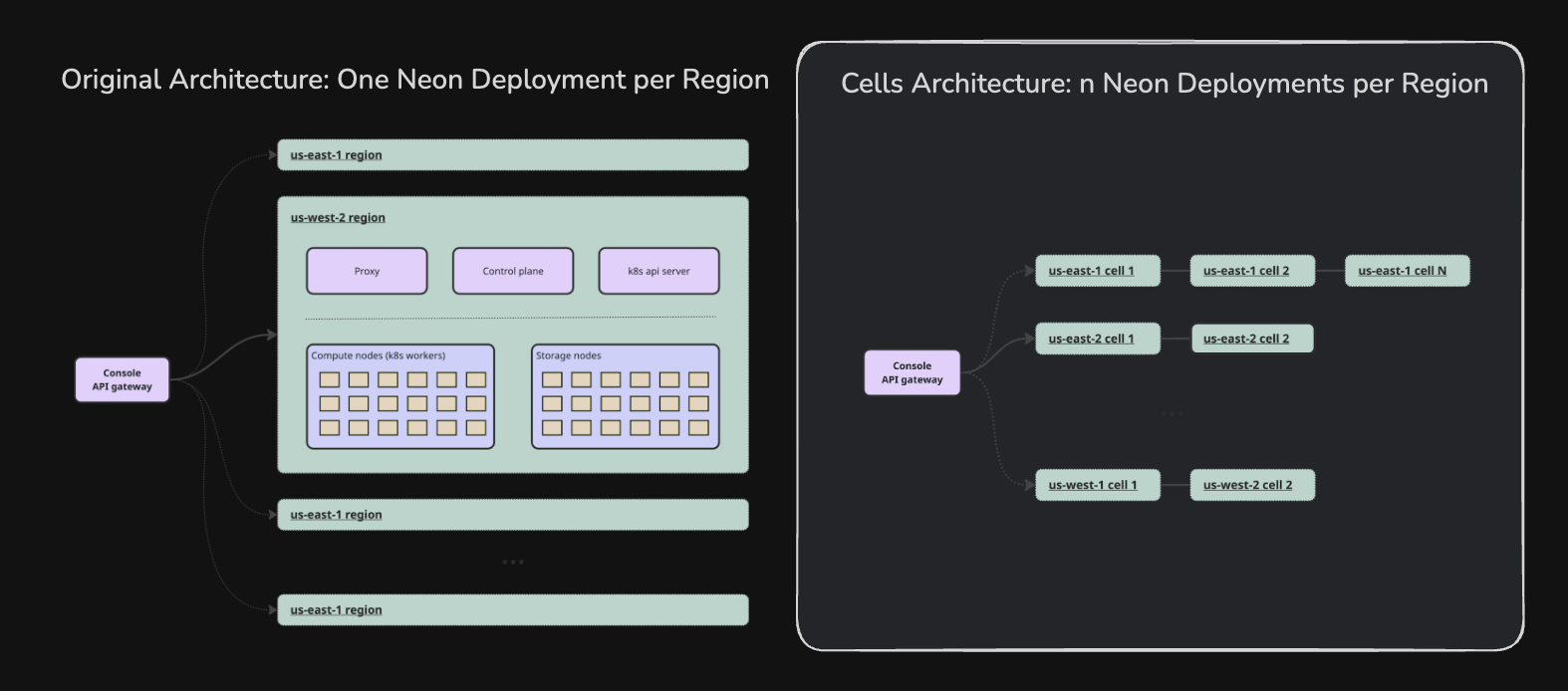
This was a major project requiring substantial changes to the Terraform code that provisions regions. We planned this project, and estimated a delivery date of Q2 2025 – this would mean a launch 6 months before it was needed, and so this seemed sufficient.
However, starting in May agentic AI platforms drove sustained 5x increase in database creation in US regions and our projections were wrong.
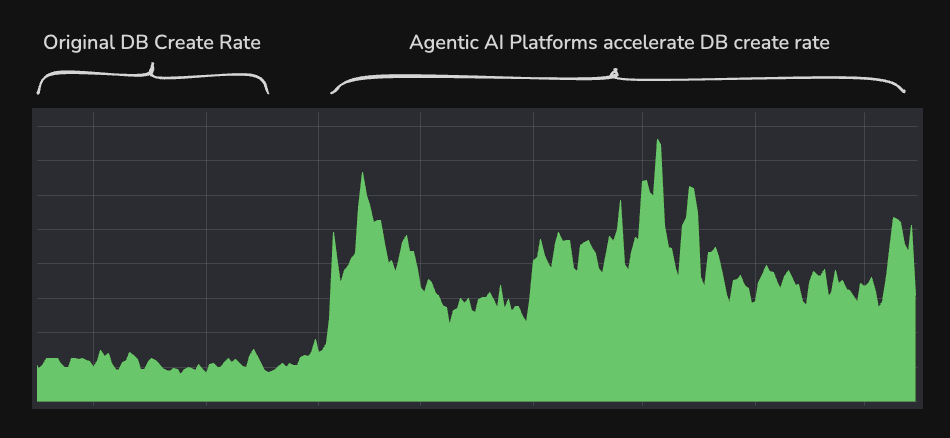
Agentic AI platforms accelerated the DB creation rate in certain regions well beyond what we projected
We made various configuration changes to keep our oversized regions functional: tuning networking, reducing our usage of the Kubernetes API to avoid EKS (Amazon Elastic Kubernetes Service) rate limits, scaling up our control plane databases, and shedding load where possible. Each of these changes bought us time to complete the Cells project, but also increased risk of failure and the amount of customer impact when failures occurred — resulting in the incidents you experienced.
Since these events, we’ve successfully shipped Cells in each of our busy regions and routed most new project creation to the new Cells. We also have the ability to deploy additional Cells quickly as load demands.
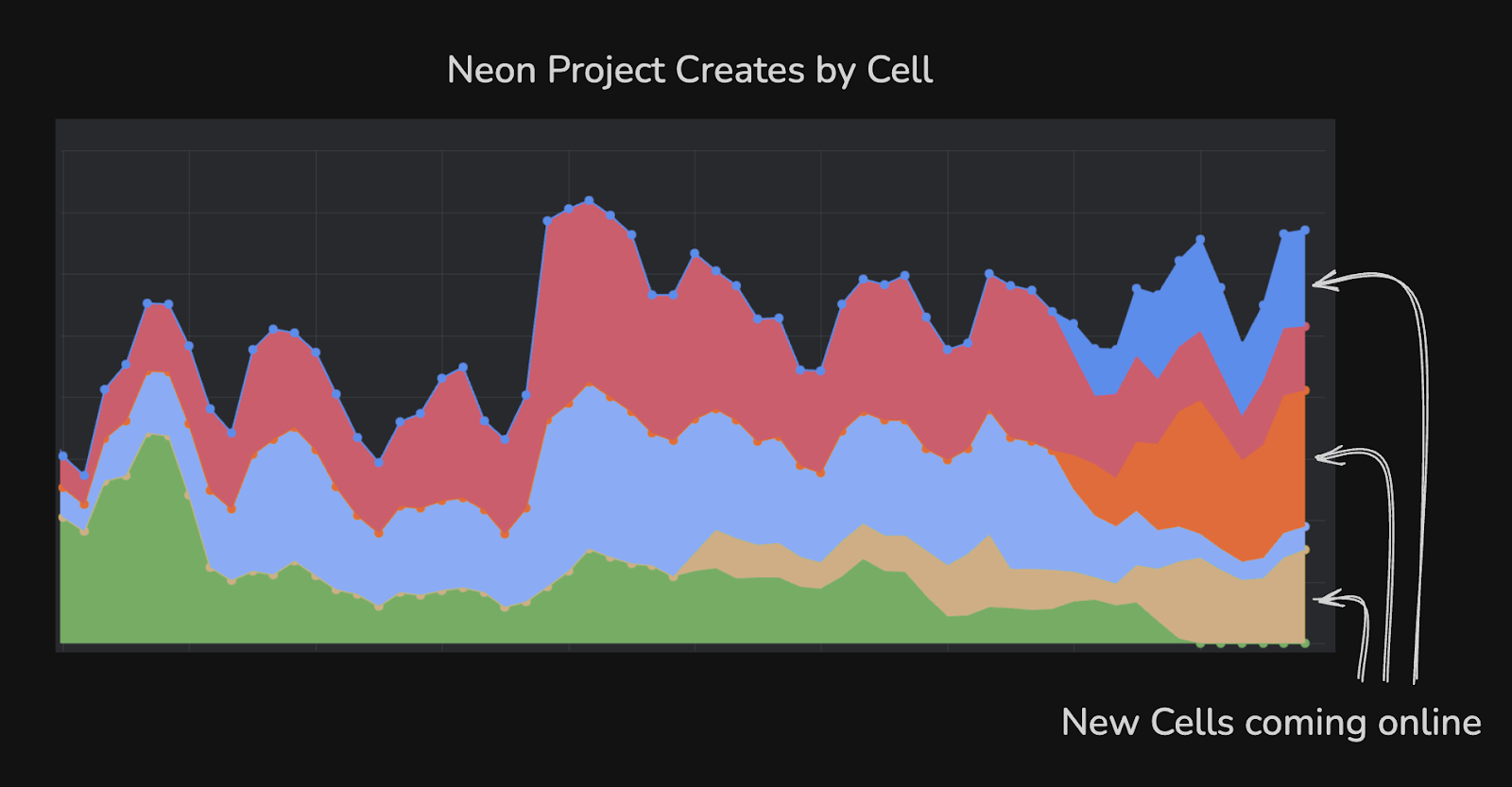
Moving new project creation to new Cells prevents old Cells from continuing to grow and helps relieve pressure on Kubernetes and the control plane. If you create a new project in AWS US today, you may notice a c-2 identifier in the URL – this indicates the Cell your project is in.

June: Metadata Handling
Database operations incidents in June were caused by scaling issues with our control plane database as a result of a 50x increase in database branch creation. A branch in Neon is a cheap operation – there’s no data copy – but that makes it fast and easy to create thousands of them. In agentic workloads, customers often use branches as “savepoints” to restore app state as their agent iterates on a codebase.
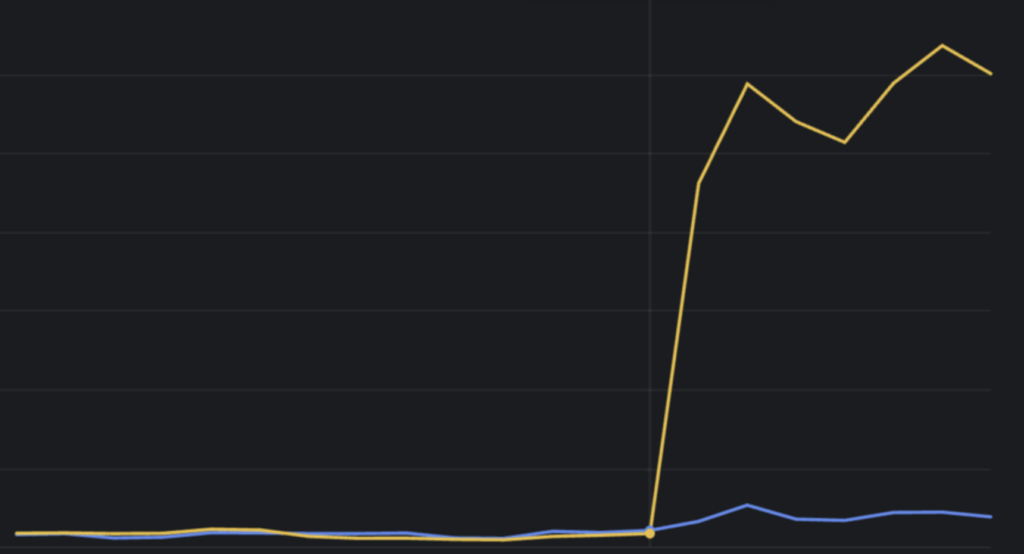
Daily branches created each day by developers (blue) vs agents (yellow)
All of this metadata is stored in Postgres instances backing our control plane. While the core of our service was more than able to sustain this sudden change in load, these shifts in metadata volume and structure had several knock-on effects:
- Billing and consumption calculations became more expensive, consuming more CPU
- Some queries switched to different Postgres execution plans, and tables became more dependent on aggressive vacuuming
- In several cases, customer-impacting issues were caused by control plane queries that went from taking a few hundred milliseconds to over a minute. We have alerting on slow and degrading query performance – but in this case, the query plan switched quickly, introducing service degradation without warning.
While we are a Postgres company, we experienced classic Postgres failure modes with increased load: query plan drift and slow vacuum. This is humbling, and will inform our roadmap to help our customers avoid the same.
Our test suites were designed around historical usage patterns which didn’t simulate highly skewed project-to-branch ratios. That meant production workloads diverged significantly from what we tested – leading to issues surfacing in production.
In this case, we had tested the system at 5x of normal load. But branch creation increased 50x. The system would have continued to function well if we had stronger limits on the number of branches both per project and per customer. One lesson here is that we need stronger limits on EVERY dimension of the workload. Rate limiting at or before our test boundaries would have saved the day.
Since then, we’ve enforced more limits, updated our tests to include high-branch-count scenarios, rewritten several queries to be more defensive against plan changes, and started redesigning our billing system to store and query data in an analytical store rather than our operational control plane database.
Up Next: Better Component Isolation
In our current architecture, the control plane handles too many responsibilities – from provisioning compute and storage to serving usage data. This is typical for fleet management systems, but there’s one key difference in our case: because we offer serverless scale-to-zero, the control plane is on the critical path for compute start when databases need to wake.
Our plan is to extract the logic responsible for managing databases – starting and suspending them – into a separate service with a much smaller surface area. This service will handle only hot-path operations (start/suspend), avoiding responsibilities like billing or provisioning. This smaller, simpler service will be more predictable, easier to operate and more resilient under load or in failure scenarios. We aim to ship elements of this in Q3, and complete in early Q4.
How Bad Was It?
These incidents primarily affected database operations (turning them on and off), so two types of customers were hit the hardest:
- Customers with idle (scale-to-zero) databases that received a connection necessitating a cold start during the incident
- Customers that deploy databases programmatically with high frequency: Customers creating a database for each of their users, agentic AI platforms, etc…
Measuring impact is tricky in a system where anyone can create a database and leave it idle for years. Counting all databases as the denominator would significantly understate real impact. We believe the percentage of affected monthly active databases is a better metric. Using that criteria:
- May: ~3.5% of monthly active databases were below 99.95% uptime
- June: ~ 0.7% of monthly active databases were below 99.95% uptime
We can and will do better. If your work was impacted by these incidents, we would like to hear from you. We want to better understand your experience so that we can improve the product beyond just reducing incidents.
Where to go from here
We know the scale of operations is only going to accelerate. Users and Agentic AI platforms are now creating more than 40,000 projects every day. The post-mortems, lessons and patches that have come from these incidents will take us a long way towards a system that can scale exponentially with best-in-class resiliency. That said, there will always be more work, new emergent usage patterns, and more scale. We know that building trust doesn’t happen overnight, we are committed to being more communicative, transparent and responsive about the service we’re building going forward.


