









note
This is a cross-post of an engineering blog that was originally published on Databricks. Neon and Databricks Lakebase both run on the same technology, and this engineering optimization benefits customers of both platforms.
Ensuring customer databases are always available is one of the most important things we do in Neon and Lakebase. We’ve designed the system with redundancy at every level, automatically failing over and recovering your database in the event of hardware or software failures.
In a large-scale system, such unplanned failures are a statistical expectation, but for an individual database, they’re not that frequent. For an individual database, planned maintenance tends to cause more workload disruption. After all, a typical database is patched more frequently than it experiences hardware failure.
Today, nearly every database provider operates with maintenance windows: scheduled periods where your database severs all active connections and gets updated and restarted in a process that can take anywhere from a few seconds to minutes. While Neon lets you schedule updates at a time that’s optimal for you, it’s still a brief interruption when it happens.
We think we can do better. This blog post is the first in a series on how we’re leveraging the lakebase architecture with separation of compute and storage to eliminate the impact of planned maintenance entirely. Our goal: make version updates and security patches completely unnoticeable.
In this post, we’ll cover prewarming: a technique that prevents any performance degradation that follows a database restart. In future posts, we’ll discuss improvements to the failover process itself and additional optimizations that bring us closer to true zero-downtime patching.
The Problem with Cold Restarts
The challenge with restarting Postgres is that in-memory caches (specifically the buffer cache and local file cache) are lost. Even though the database is back online very quickly (1 second @ P99), the workload may experience a slowdown in the first minutes after restart – we saw a ~70% reduction in pgbench TPS. This is due to a low cache hit ratio while data is read back from storage and the cache warms up. While this might seem like only a performance problem, it can be an availability issue if the slowdown is severe enough that the database cannot keep up with the workload and timeouts occur.
Techniques to address this exist in Postgres: pg_prewarm can be used to warm up buffer caches. However, this runs after a restart when the workload is already impacted. Streaming replication can be used to set up a replica, which can be prewarmed before failing over to it (promoting it to primary). However, this requires creating a full replica and carefully orchestrating the prewarming before failover.
Prewarming on Neon’s lakebase Architecture
In the lakebase architecture, we combine stateless, elastic compute nodes with disaggregated, shared storage. The compute nodes employ local caches to deliver maximum performance without sacrificing serverless properties. While the cache faces the same cold-start issues outlined above, we have more options with the Lakebase architecture.
Since Neon’s Postgres compute replicas are stateless, we can spin them up and down on demand. We utilize this and combine it with automatic prewarming on planned restarts to minimize the performance impact on the workload. This is how it works:
- A new version of Neon’s Postgres compute image becomes available. You receive a notification and can schedule the restart for a time that works for you.
- Shortly before the scheduled time, our control plane spins up a new Postgres compute in the background. You don’t see it, and you’re not billed for it. The current primary’s workload is unaffected.
- A list of pages in the current primary’s cache is sent to the new compute. The new compute loads those pages into cache from our shared storage tier without impacting the primary.
- The new compute subscribes to the WAL (write-ahead log) to keep its cache up to date. For efficiency, unlike a normal Postgres replica, it can ignore all WAL records that do not affect its cache. It gets the WAL from our Safekeepers, putting no additional load on the primary compute.
- When prewarming is complete, we quickly shut down the old primary, promote the new compute to primary, and switch it in. Promotion uses the standard pg_promote from OSS Postgres and does not restart the database server.
BEFORE:
AFTER:
With Neon’s lakebase architecture, you get this at no additional cost, without paying for additional replicas. All planned restarts of read/write endpoints in all regions are now performed this way without you having to do anything. Soon we’ll be extending it to read-only endpoints as well.
Results
To measure the impact of cold caches, we ran 10 GB pgbench (scale factor 670) on a database while restarting it – first with prewarming enabled, then without prewarming . The first chart shows a read-only workload (pgbench “select only”), while the second shows a read-write workload (pgbench “simple update”).
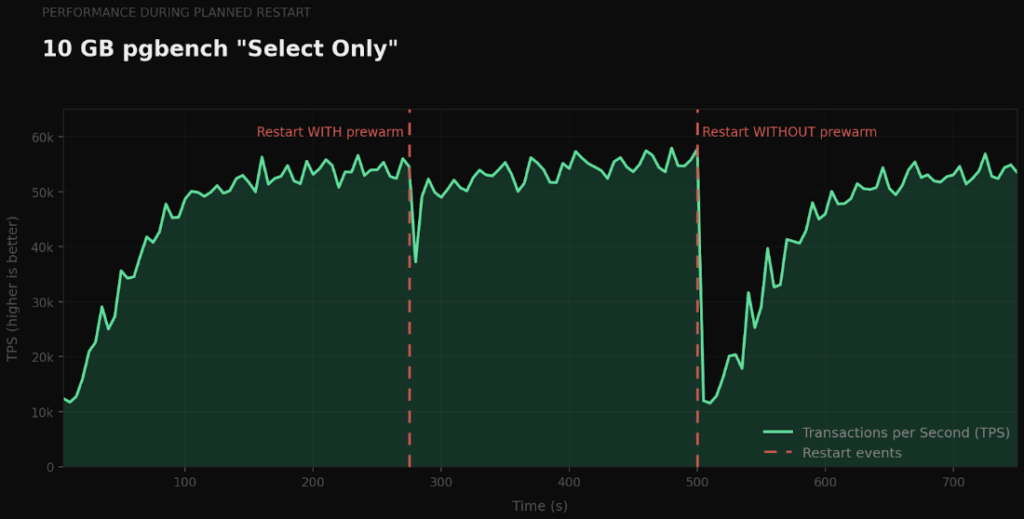
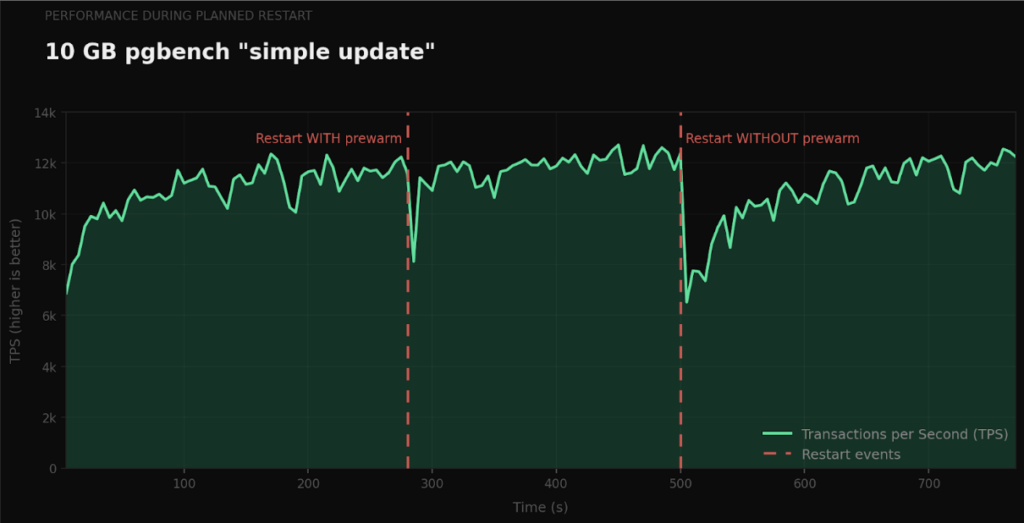
In both cases, we see that throughput recovers nearly instantly with prewarming. Without prewarming, recovery is much slower while the cold cache is warming up. The difference is starkest for the read-only workload because prewarming improves the cache hit ratio which helps reads proportionally more than writes.


