









Once upon a pipeline…
It was a nice summer evening, and our CI lived happily in a familiar castle: Hetzner. Bare-metal towers gave us everything we needed, with cheap CPU and RAM per unit, free internal traffic, and huge local disks to hoard caches like dragons guard gold.
Our workflows were built to feast on those perks: fat local caches, artifact reuse, predictable runners that never disappeared in the night… For years, life in the castle was good.
Then, life happened. Security and compliance needs grew, and we had to move to a new, much larger castle: AWS. Our migration (as it often happens when you move castles) was rushed and bumpy, and we didn’t have time to check all the dark corners.
And just like that, our cozy home turned overnight into a haunted house. A very expensive haunted house.
Act I: When Old Charms Turn Into Ghosts
Until the migration, our workflows had been written for an always-on, bare-metal world. In the cloud, though, our old tricks began to haunt us:
- Ephemeral runners added startup delays (a minute here, five there) and under load those delays multiplied before a single test even ran.
- Caching turned cold. Artifacts we once reused freely now vanished between runs, forcing full rebuilds.
- Compliance rules rewrote the spellbook. Every stage of the pipeline had to meet stricter standards end-to-end.
Because the move happened under tight deadlines, we had little time to adapt. With tight deadlines, we started fighting fires with the quickest spell: more compute.
The result was a pipeline that suddenly felt possessed. Our bill started screaming louder than a banshee.
Act II: Numbers From the Crypt
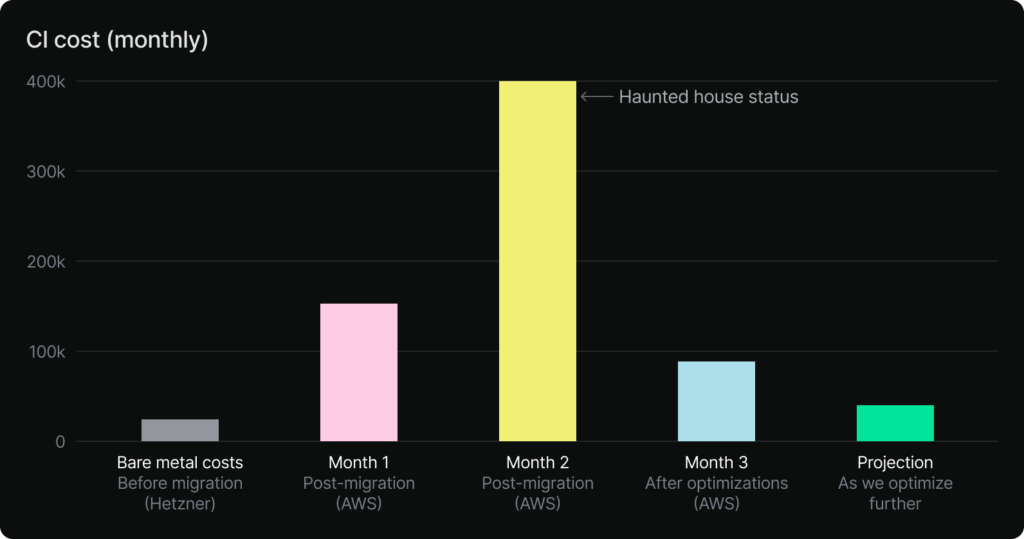
To give you an idea of our baseline costs, they were around $30k before the migration (~$15k of Hetzner infra plus ~$15k for the CI of our main repo).
The context
Back then we only had AMD builds (no ARM), some tests were disabled, and PRs didn’t trigger cloud E2E checks. It was a smaller world of fewer platforms, fewer tests, fewer surprises.
Then came the first month in AWS after our rushed migration: the bill had climbed to around $150k.
We expected it to be higher, but we got a bit spooked.
Another month went by. This time the bill got close to ** $400k **.
Now the fear was real.
Act III: What the Wise Owl Saw
If the cost spike sounds worse than “cloud is pricey,” that’s because it was. Once the terror settled, we realized a few things:
- Scope grew (by design). We expanded beyond the smaller Hetzner setup: added ARM builds, re-enabled tests, and turned on cloud E2E paths for PRs that hadn’t triggered them before. More jobs, more artifacts, more compute.
- Migration overhead was real. Ephemeral runner bootstrap time landed on the critical path, and our bare-metal caching patterns didn’t translate. We “paid” in cold starts and cache misses until the new system warmed up.
- Compliance and platform hardening added weight. Stricter isolation and provenance checks increased per-job overhead – images, policies, scanning, all of it. Some of our old shortcuts simply weren’t acceptable anymore.
So while the raw numbers looked terrifying, they weren’t pure waste. Our ≈ $30k baseline covered a far narrower workload.
Still… It was time to roll up our sleeves.
Act IV: The Exorcism
Once we’d cleared the compliance gates and shut the doors of the old Hetzner castle for good, it was time to do some real work:
- We mapped hot paths
- We trimmed cold starts
- We re-engineered caching for our new, ephemeral world
- We separated bare-metal assumptions from cloud-native realities
- We tuned the fleet to use the right kind of capacity for the right kind of workload
- Most importantly, we stopped fighting every fire with raw compute
The month after that terrifying bill, things started looking much better: costs dropped 50%, while CI times held steady or even got faster on several paths.
We didn’t stop at survival though. Once the lights were back on and the ghosts were gone, we started exploring every corridor of our new, big castle to see what else could be improved. And of course, we found clear paths to squeeze more value:
- Right-sizing compute to match workload patterns
- Caching smarter, not just harder
- Separating build classes so expensive jobs only spin up when truly needed
- Automating the boring bits, so no one has to cast manual spells at 2 a.m. again
By staying on this path, our costs keep moving down to $100k and kept trending down for the following months.
This was still higher than the bill we started with, but not at all bad considering the much higher compliance and security standards and that we’re no longer sacrificing developer productivity with the new setup.
For a journey that began with screams in the dark, that’s not a bad ending.
Epilogue
Lessons learned by candlelight
Moving fast can haunt you later, and cleaning up your own ghosts looks more like grind than magic.
There was no witchcraft involved in this exorcism, just better CI. There was no single silver bullet but careful debugging, patient iteration, and a willingness to laugh at our own mistakes along the way.
Our haunted castle of cold starts and ballooning bills now feels like home again – faster, cheaper, and far better defended against whatever spirits come next.
And like every good Halloween tale, this one ends at dawn: with the monsters named, the lessons learned, and a CI that won’t vanish when the sun comes up.


