









Neon & Inngest
This blog post is a collaboration with Inngest, a platform for building serverless workflows and durable API endpoints that automatically handle retries, state, and long-running logic.
Every AI lab is shipping research agents. OpenAI’s Deep Research, Perplexity, and Gemini’s research mode. These products are not simple RAG pipelines. Recent papers like DeepResearcher and Step-DeepResearch formalize what makes them work: a recursive loop of planning, searching, learning, and reflecting, where the agent decides when to go deeper and when to stop.
The interesting part isn’t that AI can search the web. Three things stand out from the research:
- The recursive structure: research is not a single query. It is a tree of queries that branches based on what the agent learns at each level.
- The four atomic capabilities (from Step-DeepResearch): planning and task decomposition; deep search and information gathering; reflection and cross-validation; and report generation.
- Memory across sessions: most research agents start from scratch every time. What if yours got smarter?
This article walks through building a recursive research agent that implements these ideas with a practical stack: Neon (serverless Postgres + pgvector) for persistence and semantic memory, Inngest’s durable endpoints for fault-tolerant API endpoints, and Claude Code to vibe-code the implementation.
What we are building:
- A recursive research agent with real-time progress tracking
- Durable execution that survives failures, retries, and restarts
- Semantic memory with pgvector, so new research builds on past findings
- A Next.js UI that shows live progress, source discovery, and research history
The full source code is available on GitHub.
The stack – and why each piece matters:
| Component | Role |
|---|---|
| Neon | Sessions, events, sources, and learnings in one database. Embeddings live next to relational data, no separate vector DB. The serverless driver means no connection pool headaches. |
| Durable Endpoints | Each API call, search, and LLM invocation is a retriable step. If Exa times out on search #14 of 30, it retries that step rather than failing the API request. |
| Claude | Generates clarification questions, search queries with reasoning, learning extraction with source rationale, and the final report with citations. |
| Exa | Neural web search that returns full page content, not just snippets. |
| OpenAI | text-embedding-3-small for 1 536-dim embeddings stored in pgvector. |
| Next.js | The front-end and API stack powering the demo. |
The database layer: schema, events, and semantic memory
Everything lives in one Postgres database. Sessions, progress events, relational data, and vector embeddings. No separate vector database, no Redis for events, no S3 for reports. One connection string, one deployment.
The four tables
The system state lives in four Postgres tables:
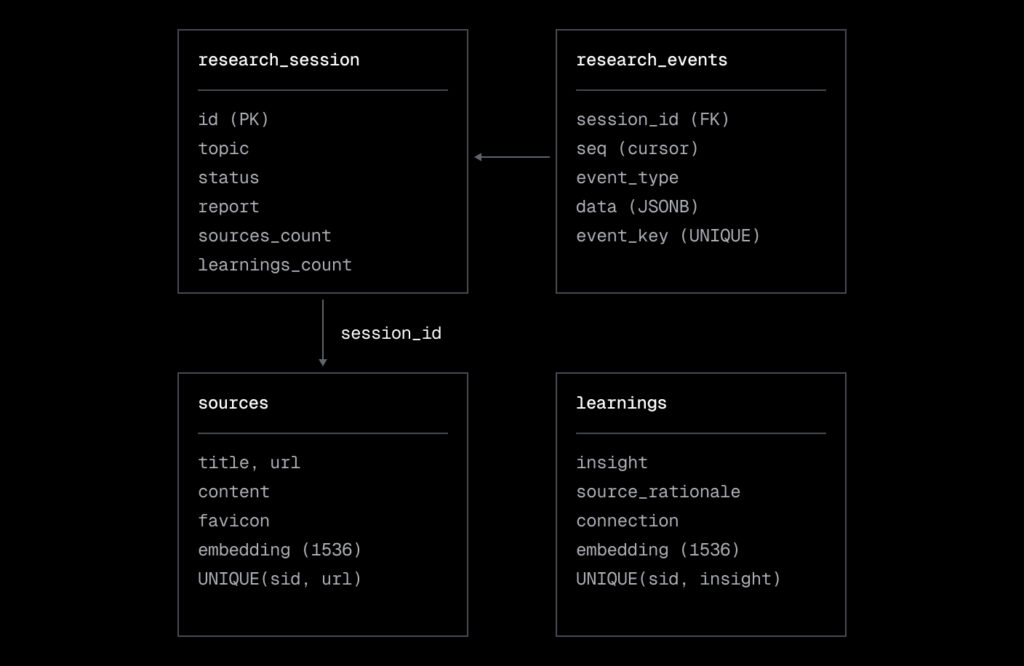
- research_sessions is the session ledger: topic, status, and the final report.
- research_events stores progress events with sequence numbers for cursor-based polling.
- sources holds web sources with pgvector embeddings for semantic recall.
- learnings contains extracted insights with embeddings, linked back to their session.
Polling-based real-time progress
The client polls /api/research/events?researchId=X&cursor=N every 500ms. Events have monotonic sequence numbers. The cursor ensures no duplicates and no missed events:
No WebSockets needed. This works in any serverless environment because each poll is a stateless HTTP request.
Semantic memory: learning across sessions
Most AI tools treat each session as a blank slate. Our agent remembers. Before generating search queries for a new session, it queries pgvector for semantically similar learnings and sources from past sessions.

This is a practical implementation of the “reflection” capability from the Step-DeepResearch paper. The agent is not just reflecting on the current session. It is reflecting across its entire research history.
The recall step runs a pgvector query using cosine distance.
Prior knowledge gets injected into the search query generation prompt as context:
Here are relevant findings from previous research sessions:
Prior Insights:
- [From "AI in healthcare"] FDA approved 171 AI medical devices in 2023
- [From "AI in healthcare"] Most medical AI focuses on radiology and pathology
Build on this existing knowledge rather than duplicating it.This turns “generate queries about X” into “generate queries about X, knowing that previous research found Y and Z.” The agent naturally avoids re-searching known territory and focuses on what is new.
Why Neon fits
Three things make Neon a good fit for this architecture:
- Serverless driver (
@neondatabase/serverless): each query is an HTTP request. No persistent connections, no pool management. This is critical when running inside Inngest’s durable endpoint, where long-lived connections are not practical. - pgvector built-in: embeddings live in the same database as sessions and events. One connection string, one deployment.
- Neon MCP server: Claude Code can create the database, run the schema, and query data directly from the terminal during development.
Claude Code prompt: database schema, helpers, and event store
Set up the Neon database layer.
Create schema.sql with four tables: research_sessions (id, topic, status, clarifications JSONB, report, sources_count, learnings_count, created_at, completed_at), research_events (session_id FK, seq auto-incrementing via subquery, event_type, data JSONB, event_key with UNIQUE constraint on session_id + event_key), sources (session_id, title, url, content, favicon, embedding vector(1536), UNIQUE on session_id + url), learnings (session_id, insight, source_url, source_rationale, connection, embedding vector(1536), UNIQUE on session_id + insight). Add IVFFlat indexes on the embedding columns.
Create src/lib/db.ts wrapping @neondatabase/serverless with a lazily-initialized sql tagged template function. Create src/lib/embeddings.ts with generateEmbedding(text) and generateEmbeddings(texts) using the Vercel AI SDK’s embed/embedMany with OpenAI text-embedding-3-small.
Create src/inngest/event-store.ts with createSession() (INSERT into research_sessions), emitProgress() (idempotent INSERT with ON CONFLICT DO NOTHING and auto-incrementing seq), and getEventsSinceCursor() (SELECT with cursor returning events array, next cursor, and session status).
Create src/types.ts with shared frontend types: ClarificationQuestion, Source, ResearchState, LogEntry, DurabilityMetrics, PastSession.
The research engine: LLM functions, algorithm, and durable execution
From papers to architecture
DeepResearcher describes emergent cognitive behaviors that arise from training research agents: planning (formulating and adjusting a search strategy), cross-validation (verifying findings across sources), self-reflection (refining queries when results don’t match), and epistemic honesty (knowing when to stop).
Step-DeepResearch takes this further. The paper formalizes these behaviors as four atomic capabilities and frames Deep Research as long-horizon decision-making over them.

Our implementation maps these capabilities onto concrete functions. Plan is generateClarificationQuestions() and generateSearchQueries(). Search is Exa web search. Reflect is extractLearnings() with source rationale, connections, and follow-up queries. Synthesize is generateReport().
Structured LLM output
Before starting the research, the agent generates clarification questions with suggested options. This implements Step-DeepResearch’s “planning” capability, decomposing a broad topic into a focused research direction. Claude generates structured output validated by Zod:
{
questions: [
{
id: "q1",
question: "What aspect of quantum computing interests you most?",
options: ["Hardware", "Algorithms", "Error correction", "Applications"]
},
...
]
}Each search query includes a reasoning field (why this angle matters) and an angle field (what perspective it covers). This mirrors DeepResearcher’s emergent planning behavior: the agent explains its search strategy before executing it. The reasoning is not just for debugging. It gets displayed in the UI and emitted as progress events, so the full reasoning chain is persisted in Neon.
When extracting learnings from search results, the agent also produces:
- Source rationale: why this source was relevant to the query
- Learning connections: how this finding relates to previously accumulated learnings
- Follow-up queries: what questions this finding raises (this drives the recursive loop)
- Synthesis notes: meta-observations about how findings from different sources connect
The follow-up queries are what make the algorithm recursive. After extracting learnings at depth 3, the agent generates new questions to explore at depth 2, informed by what it just learned.
The recursive algorithm
The user enters a topic, Claude generates clarification questions, then search queries with reasoning. From there, the agent enters a depth loop:
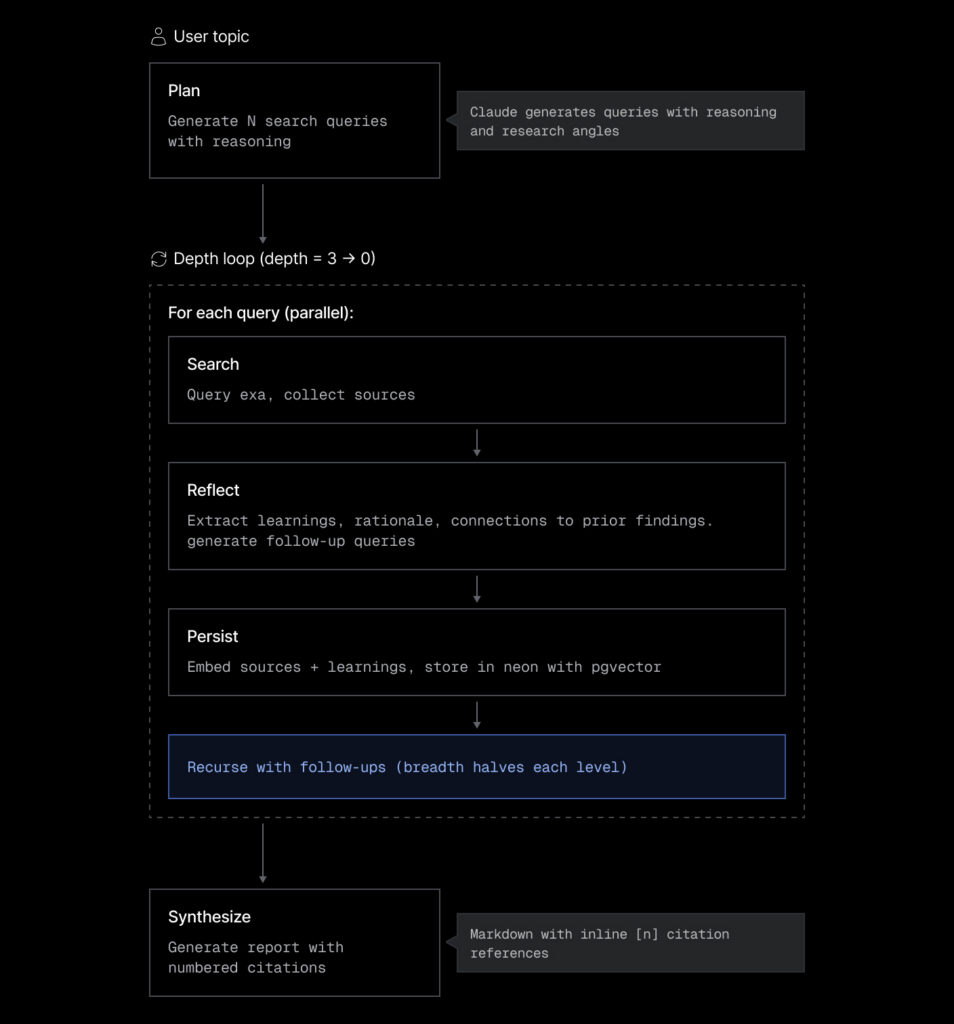
At each depth level, the agent searches all queries in parallel, extracts learnings from the results (also in parallel), then collects follow-up queries and recurses.
Durable execution with Inngest
A deep research session makes 30+ external API calls across several minutes: Exa searches, Claude analyses, OpenAI embeddings, Neon inserts. Any single call can fail. Without durability, a timeout on search #14 means starting over from search #1, a rate limit on Exa’s API means losing all accumulated progress, and a server restart means the entire session is gone.
Inngest’s step.run() wraps each external call. Each step is:
- Retriable: if it fails, only that step retries (up to 3 times)
- Memoized: if the whole function replays, completed steps return their cached result instantly
- Identifiable: step IDs like
search-d3-a1b2c3d4ensure deterministic replay
The main research endpoint is defined as an Inngest durable endpoint using inngest.endpoint(). It receives a standard Request and orchestrates the full workflow through sequential durable steps:
export const GET = inngest.endpoint(async (req: NextRequest) => {
// Step 0: Create session in Neon
await step.run("create-session", async () => {
await createSession(researchId, topic, clarifications);
});
// Step 1: Recall prior research (semantic memory)
const priorKnowledge = await step.run("recall-prior-research", async () => {
const topicEmbedding = await generateEmbedding(topic);
const relatedLearnings = await sql`
SELECT l.insight, s.topic as from_topic
FROM learnings l
JOIN research_sessions s ON l.session_id = s.id
WHERE s.id!= ${researchId}
ORDER BY l.embedding <=> ${JSON.stringify(topicEmbedding)}::vector
LIMIT 10
`;
return { relatedLearnings, relatedSources };
});
// Step 2: Generate search queries (informed by prior knowledge)
const queries = await step.run("generate-queries", async () => {
return await generateSearchQueries(topic, clarifications, breadth, priorKnowledge);
});
// Step 3: Recursive deep research (many nested steps)
await deepResearch(researchId, topic, queries, depth, depth, breadth, accumulated, existingUrls);
// Step 4: Generate report
const report = await step.run("generate-report", async () => {
return await generateReport(topic, accumulated);
});
});Idempotency at every layer
Durability requires idempotency. The system handles this at three levels:
- Step level: deterministic step IDs (
search-d$\{depth\}-$\{hash(query)\}) prevent duplicate execution on replay - Event level: progress events use content-based keys, with
ON CONFLICT DO NOTHINGin Postgres - Data level: sources and learnings tables have
UNIQUE (session_id, url)andUNIQUE (session_id, insight)constraints
This matters because Inngest replays the entire function on step failure. Without idempotent writes, a retry could duplicate sources or emit duplicate progress events. The ON CONFLICT DO NOTHING pattern in Postgres makes every INSERT safe to re-execute.
Claude Code prompt: search and LLM functions
Create the search and LLM integration layer. In src/inngest/search.ts, wrap the Exa SDK (exa-js) to search the web using searchAndContents() with numResults: 5, useAutoprompt: true, and text: { maxCharacters: 2000 }. Return results as { title, url, content, favicon } objects.
In src/inngest/types.ts, define types for Source (with content field), AccumulatedResearch, QueryWithReasoning (query + reasoning + angle), LearningWithReasoning, and ExtractedLearnings. In src/inngest/utils.ts, create hashQuery(query) using crypto SHA-256 (first 8 hex chars) and calculateProgress(depth, maxDepth).
In src/inngest/llm.ts, implement four functions using Claude Sonnet via the Vercel AI SDK with Zod schema validation: (1) generateClarificationQuestions(topic) returning questions with options, (2) generateSearchQueries(topic, clarifications, breadth, priorKnowledge) returning queries with reasoning and angles, injecting prior knowledge context when available, (3) extractLearnings(topic, query, sources, existingLearnings) returning learnings with source rationale and connections plus follow-up queries with reasoning, (4) generateReport(topic, accumulated) generating a markdown report with inline [N] citation references.
Claude Code prompt: recursive algorithm
Build the recursive deep research algorithm in src/inngest/deep-research.ts.
The function deepResearch takes a research ID, topic, queries array, depth, maxDepth, breadth, an AccumulatedResearch accumulator, and a Set of existing URLs.
At each depth level: (1) search all queries in parallel using Exa via step.run(), deduplicating by URL against existingUrls, (2) extract learnings from each result using Claude via step.run(), collecting follow-up queries, (3) persist new sources and learnings with OpenAI embeddings to Neon via step.run(), using ON CONFLICT DO NOTHING for idempotency.
Emit progress events between steps using emitProgress() from the event store.
After processing all queries at a depth level, collect follow-up queries, halve breadth (nextBreadth = Math.ceil(breadth / 2)), cap follow-ups to nextBreadth * queries.length, and recurse with depth – 1.
Step IDs must include depth and a hash of the query for deterministic replay (e.g. search-d${depth}-${hashQuery(query)}).
Claude Code prompt: API routes and durable endpoints
Create the API routes.
(1) src/app/api/research/clarify/route.ts: an Inngest durable endpoint (https://www.inngest.com/docs/learn/durable-endpoints) that takes a topic query param and returns clarification questions by calling generateClarificationQuestions() inside a step.run(). (2) src/app/api/research/route.ts: the main Inngest durable endpoint that receives researchId, topic, clarifications, depth, and breadth as query params.
It orchestrates: step.run(“create-session”) to create the session, step.run(“recall-prior-research”) to embed the topic and query both learnings and sources tables using pgvector cosine distance (<=> operator), step.run(“generate-queries”) to generate search queries with prior knowledge context, then deepResearch() for the recursive loop, then step.run(“generate-report”) to synthesize findings, and finally update the session as complete.
Emit progress events between each phase. (3) src/app/api/research/events/route.ts: a plain Next.js route handler (not durable) that takes researchId and cursor query params and returns events via getEventsSinceCursor(). (4) src/app/api/research/history/route.ts: a plain route handler that queries research_sessions and their associated sources, returning past sessions ordered by date.
The frontend: real-time research visualization
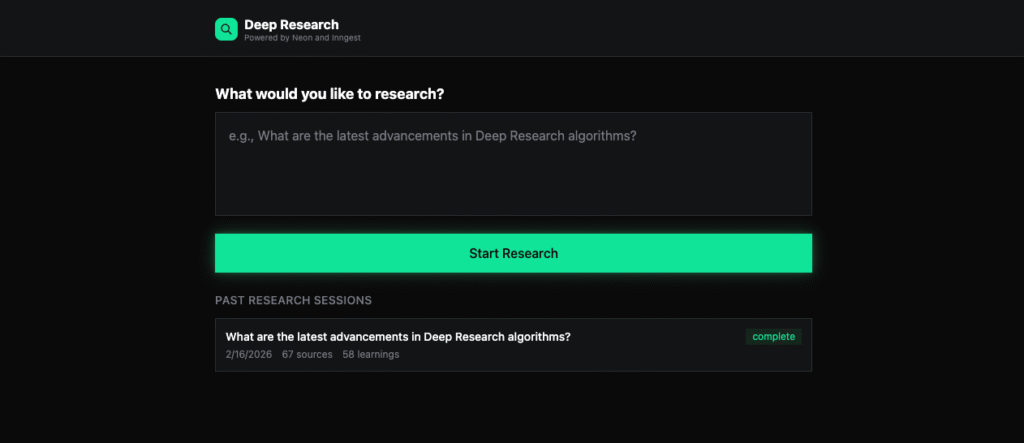
The interface cycles through six states: idle (topic input with past sessions list), loading-clarifications, clarifying (answering questions), researching (live progress), complete (report view), and error.
A useResearch hook manages all state transitions and event processing. During research, the hook polls /api/research/events every 500ms, processing each event to update progress, sources, reasoning, and step statuses.
Live progress during research
During the researching state, the UI displays:
- A progress bar that fills as depth levels complete
- Current reasoning activity with expandable history
- Source cards appearing in real-time as they are discovered
- A “prior knowledge” banner when the agent recalls past findings
The reasoning display is important. It shows the agent’s decision-making in real time, including query angles, source rationale, and synthesis notes. This makes the research process transparent rather than treating it as a black box.
Past sessions and memory visibility
The idle state shows past research sessions. Each card displays the topic, date, source count, and status. Clicking a completed session loads its full report with all sources.
This makes the semantic memory tangible. The user can see knowledge accumulating across sessions. When the agent recalls prior learnings during a new session, the connection to past work is visible.
Claude Code prompt: research UI
Build the research UI as a Next.js app.
Create a useResearch hook in src/hooks/useResearch.ts managing six states: idle, loading-clarifications, clarifying, researching, complete, error. The hook should poll /api/research/events every 500ms during research, processing events by type (prior-knowledge, clarify-complete, queries-generated, search-start, source-found, learning-extracted, synthesis, follow-up-reasoning, depth-complete, report-generating, complete, error, step-retry, step-recovered) to update progress, sources, reasoning history, and step statuses.
Deduplicate sources by URL to handle Inngest replays. Create these components: (1) TopicInput with a textarea for the topic and a list of past research sessions, (2) ClarificationForm with numbered questions, clickable option chips, and text input fallbacks, (3) ResearchProgress with a progress bar, live reasoning display with expandable history, source cards appearing in real-time, and a prior knowledge indicator, (4) ResearchComplete with a completion summary, collapsible sources list, and a markdown report rendered with react-markdown and clickable citation badges, (5) ExecutionLog showing timestamped events with color-coded types, (6) shared ui.tsx primitives (LoadingSpinner, ProgressBar, CitationText).
Wire everything in src/app/page.tsx which renders the appropriate component based on the current research state.
Wrap up
This project implements the core ideas from DeepResearcher and Step-DeepResearch in a practical full-stack application:
- Recursive search with breadth reduction and follow-up generation
- Four atomic capabilities: planning (clarification + query generation), search (Exa), reflection (learning extraction with rationale), and synthesis (report with citations)
- Durable execution via Inngest, where every step is retriable and memoized
- Semantic memory via Neon pgvector, where knowledge compounds across sessions
- Real-time progress via cursor-based polling on Neon
The full source code is available on GitHub.
Appendix: Taking it further with Claude Code
Here are some prompts to extend this demo:
Curated memory. The current implementation saves all sources and learnings to memory automatically. A more useful approach would let users choose what to keep:
Add a post-research review step where the user can select which sources and learnings to persist to memory. Add checkboxes to the ResearchComplete view next to each source and learning. Only embed and store the selected items.
Source quality scoring. Not all sources are equally valuable. Weighting them improves recall:
Add a quality_score column to the sources table. After extracting learnings, have Claude rate each source on relevance (1-5). Use the score as a weight when recalling prior knowledge: ORDER BY (1 – (embedding <=> $vector)) * quality_score DESC.
Branching research. Sometimes you want to fork a completed session and explore a different direction:
Allow users to fork a completed research session into a new one that starts with all the parent’s accumulated learnings. Implement this as a new API route that copies the session’s learnings as the initial priorKnowledge for the child session.


